── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
✖ dplyr::select() masks MASS::select()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Code
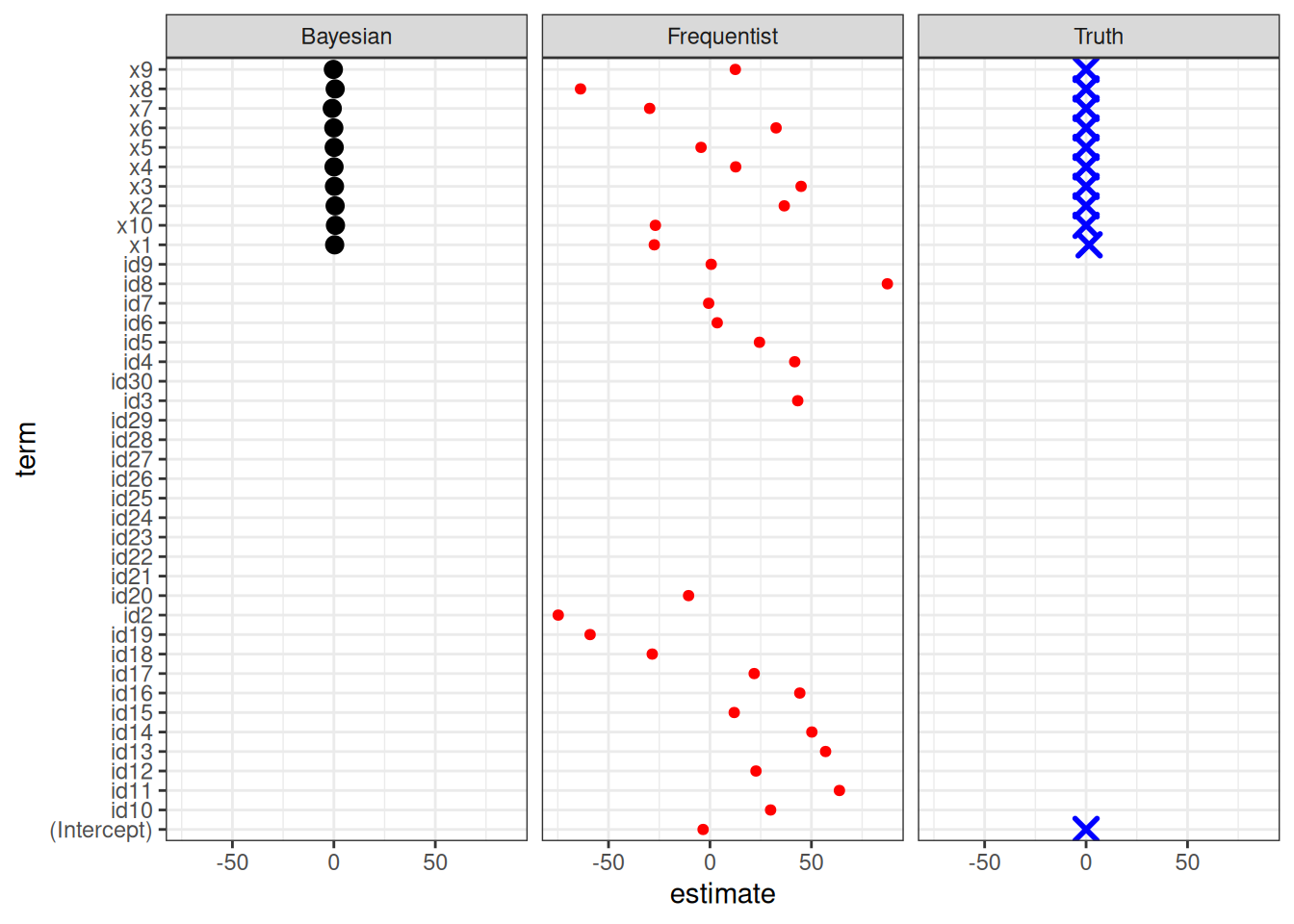
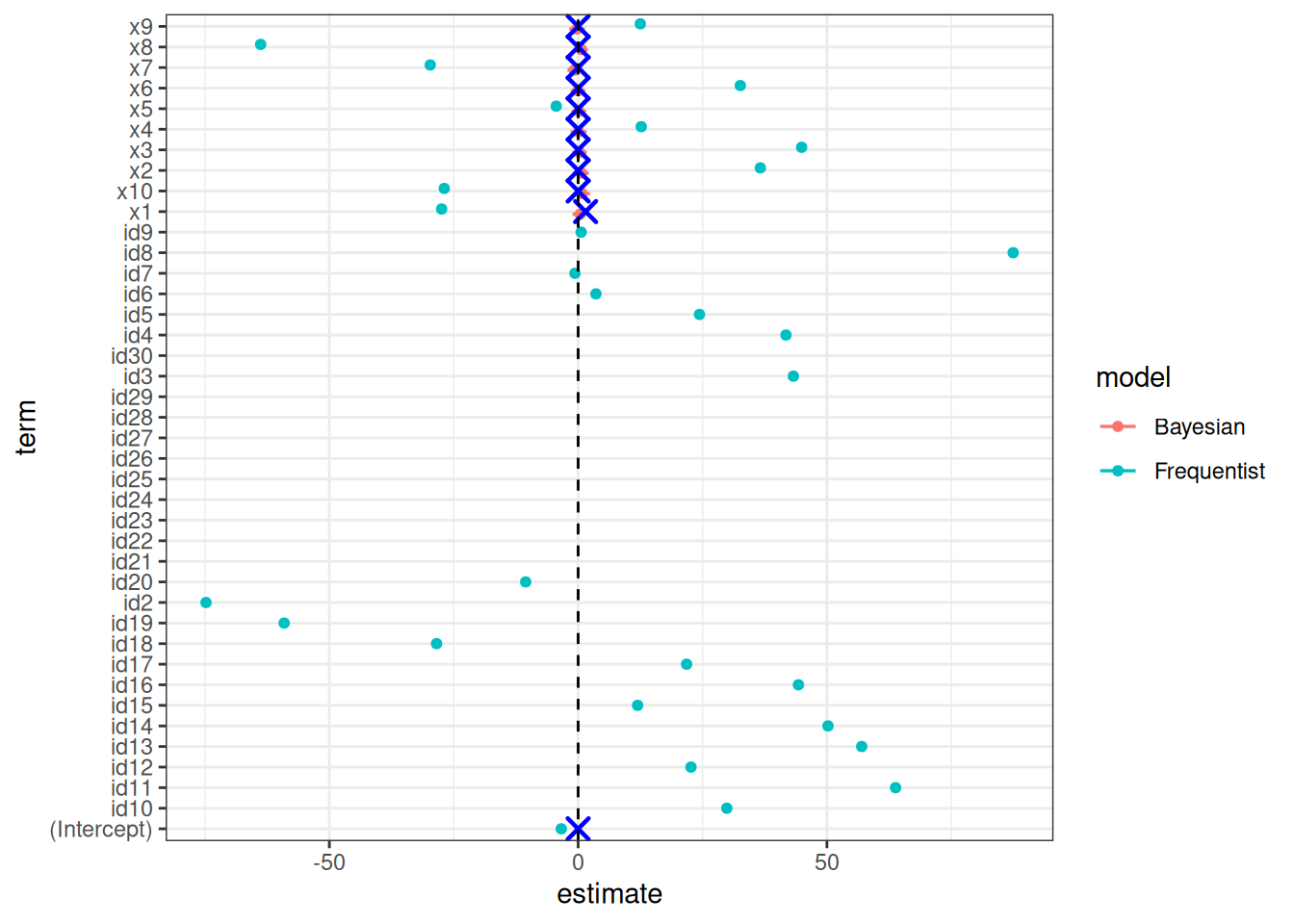
set.seed(12)# -----------------------------# Simulate correlated predictors# -----------------------------n <-30p <-10Sigma <-matrix(0.9, p, p)diag(Sigma) <-1X <- MASS::mvrnorm(n, mu =rep(0, p), Sigma = Sigma)colnames(X) <-paste0("x", 1:p)# True data-generating process:# only x1 mattersbeta_true <-c(1.5, rep(0, p -1))y <- X %*% beta_true +rnorm(n, 0, 2)dat <-data.frame(y, X, id =1:n)dat <- dat |> dplyr::mutate(id =as.factor(id) )dat_long <- dat |> tidyr::pivot_longer(cols =starts_with("x"),names_to ="predictor",values_to ="value", )# -----------------------------# Frequentist OLS# -----------------------------fit_lm <-lm(y ~ ., data = dat)fit_lm_long <-lm(y ~ ., data = dat_long)summary(fit_lm)
Call:
lm(formula = y ~ ., data = dat)
Residuals:
ALL 30 residuals are 0: no residual degrees of freedom!
Coefficients: (10 not defined because of singularities)
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3.3873 NaN NaN NaN
x1 -27.4343 NaN NaN NaN
x2 36.6169 NaN NaN NaN
x3 44.9134 NaN NaN NaN
x4 12.6781 NaN NaN NaN
x5 -4.3991 NaN NaN NaN
x6 32.5898 NaN NaN NaN
x7 -29.7243 NaN NaN NaN
x8 -63.8061 NaN NaN NaN
x9 12.4932 NaN NaN NaN
x10 -26.9036 NaN NaN NaN
id2 -74.7875 NaN NaN NaN
id3 43.2553 NaN NaN NaN
id4 41.7687 NaN NaN NaN
id5 24.3886 NaN NaN NaN
id6 3.5718 NaN NaN NaN
id7 -0.6418 NaN NaN NaN
id8 87.4302 NaN NaN NaN
id9 0.6060 NaN NaN NaN
id10 29.8794 NaN NaN NaN
id11 63.7978 NaN NaN NaN
id12 22.6777 NaN NaN NaN
id13 56.9841 NaN NaN NaN
id14 50.2156 NaN NaN NaN
id15 11.9500 NaN NaN NaN
id16 44.2689 NaN NaN NaN
id17 21.7949 NaN NaN NaN
id18 -28.4541 NaN NaN NaN
id19 -59.0872 NaN NaN NaN
id20 -10.5432 NaN NaN NaN
id21 NA NA NA NA
id22 NA NA NA NA
id23 NA NA NA NA
id24 NA NA NA NA
id25 NA NA NA NA
id26 NA NA NA NA
id27 NA NA NA NA
id28 NA NA NA NA
id29 NA NA NA NA
id30 NA NA NA NA
Residual standard error: NaN on 0 degrees of freedom
Multiple R-squared: 1, Adjusted R-squared: NaN
F-statistic: NaN on 29 and 0 DF, p-value: NA