y x1 x2 x3 x4 x5 x6
1 -0.3619515 1.7338885 1.1572440 1.5663605 1.2414470 1.5872303 1.9987247
2 -3.8819137 -1.3474986 -0.8599374 -1.5168523 -1.3935671 -1.7076858 -1.4030663
3 -0.4420222 1.0608052 0.9437309 0.8560202 0.5639471 0.8984077 0.7050452
4 1.1413268 1.0431356 0.6160122 0.9800491 0.8826097 1.3451461 0.5586863
5 6.5306421 2.1499395 1.7871217 2.1808851 1.5457269 2.1541810 1.9213977
6 2.2434021 0.5285393 0.1133341 0.2129800 0.2390573 -0.2156071 0.5303573
x7 x8 x9 x10
1 1.5714507 1.0637851 0.9605804 1.2430034
2 -1.3452645 -2.0385995 -1.7664969 -1.6662695
3 1.0833713 0.8642306 0.8842084 1.2669940
4 0.6985452 0.9410241 0.7149090 0.9961733
5 1.6695037 1.7713908 1.9117235 1.9644211
6 0.4675085 -0.1350402 0.2512964 0.6051131Why We Need Bayesian Linear Regression
Mechanism, Interpretation, and Failure Modes of Frequentist OLS
Daniel Skak Mazhari-Jensen
2026-06-12
What is this Bayesian thing anyway?
Chat with your neighbor for 3 minutes - where/what have you heard about Bayesian inference?
:raising_hand_woman: How many have heard about Bayesian inference?
:raising_hand_woman: How many already use a Bayesian workflow?
:walking::walking_woman: Do you ?????
Never <——-> I took a course in computer science
The Core Question
Why do we need a Bayesian approach to regression - we can just use ordinary least squares?
The answer is not (only):
- philosophy
- elegance
- a matter of preference
Real regression problems are often weakly identified, noisy, unstable, and geometrically pathological.
Bayesian regression stabilizes inference.
The Frequentist Ideal
Ordinary Least Squares (OLS):
- minimizes squared residuals
- produces unbiased estimators
- provides confidence intervals and p-values
- works beautifully asymptotically
The classical linear model:
\[ y = X\beta + \epsilon \]
with
\[ \epsilon \sim \mathcal{N}(0, \sigma^2) \]
OLS estimator:
\[ \hat{\beta}_{OLS} = (X^TX)^{-1}X^Ty \]
The Hidden Assumption
OLS works well when:
- predictors are not highly collinear
- sample size is large
- signal-to-noise ratio is reasonable
- parameters are strongly identified
But real data often violate all of these simultaneously.
A More Realistic Situation
Suppose we have:
- 30 observations
- 10 predictors
- strong predictor correlation
- weak signal
- uncertain mechanisms
This is extremely common in:
- social science
- biology
- psychology
- economics
- policy research
The Data Generating Process
The truth is simple.
Only one predictor matters.
\[ y = 1.5x_1 + \epsilon \]
All other predictors have zero effect.
Yet predictors are highly correlated.
The Mechanism of Failure
With correlated predictors:
- many coefficient combinations fit equally well
- the likelihood becomes nearly flat
- tiny noise changes estimates dramatically
OLS asks:
Which coefficients minimize prediction error?
But it never asks:
Are these coefficient magnitudes plausible?
The Geometry Problem
Collinearity creates unstable directions in parameter space.
The matrix:
\[ (X^TX)^{-1} \]
becomes nearly singular.
As a result:
- coefficients explode
- signs flip
- uncertainty becomes enormous
- interpretation collapses
The Bayesian Solution
Bayesian regression adds prior information:
\[ \beta_j \sim \mathcal{N}(0,1) \]
Posterior:
\[ p(\beta \mid y) \propto p(y \mid \beta)p(\beta) \]
The prior regularizes weakly identified directions.
This changes the geometry of inference.
Important Clarification
Bayesian priors are not magic.
They encode structural skepticism.
The prior says:
Large coefficients should require strong evidence.
This is often scientifically reasonable.
Simulation Setup
We now simulate the failure directly.
- small sample
- many predictors
- high collinearity
- weak signal
The true model:
\[ y = 1.5x_1 + \epsilon \]
Only x1 matters.
Simulating Correlated Predictors
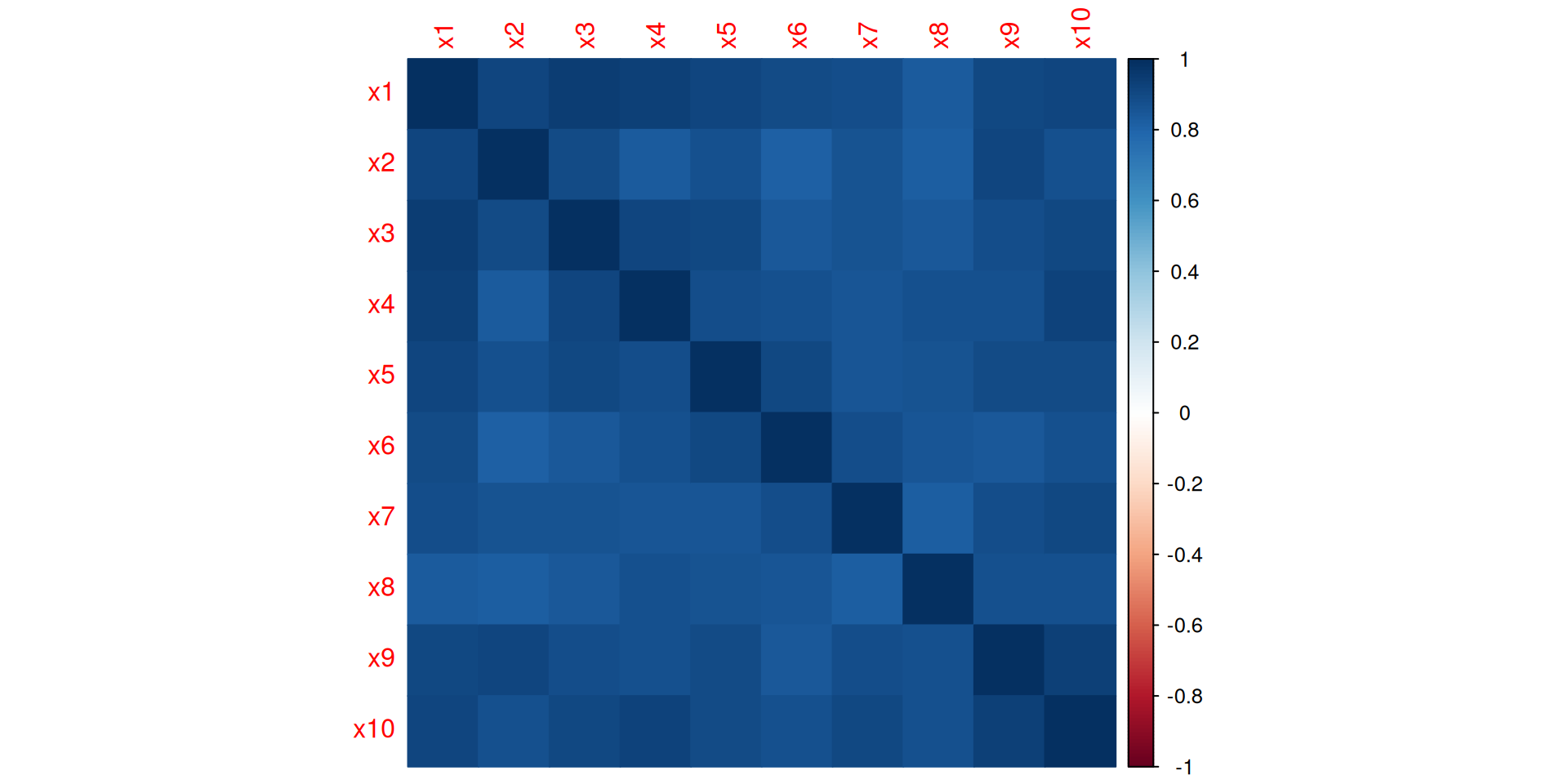
Figure 1: Correlation structure among predictors.
Frequentist OLS
Call:
lm(formula = y ~ ., data = dat)
Residuals:
Min 1Q Median 3Q Max
-3.6106 -0.9145 0.0206 0.9531 2.8211
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.28779 0.39016 -0.738 0.4698
x1 1.00890 1.93193 0.522 0.6075
x2 2.12201 1.42615 1.488 0.1532
x3 -0.03971 1.39036 -0.029 0.9775
x4 -1.13206 1.67655 -0.675 0.5077
x5 -0.13701 1.21925 -0.112 0.9117
x6 0.22854 1.22996 0.186 0.8546
x7 -2.27213 1.11660 -2.035 0.0561 .
x8 1.27474 1.05771 1.205 0.2429
x9 -2.74290 1.50399 -1.824 0.0840 .
x10 3.79090 1.60541 2.361 0.0290 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.924 on 19 degrees of freedom
Multiple R-squared: 0.6488, Adjusted R-squared: 0.464
F-statistic: 3.511 on 10 and 19 DF, p-value: 0.008964Why This Happens
Predictors are interchangeable.
The model can fit equally well using:
- huge positive x1
- huge negative x2
OLS has no mechanism preventing absurd parameter values.
It only optimizes fit.
The Frequentist Interpretation Problem
Researchers now face impossible interpretation.
Questions become unstable:
- Which variables matter?
- Which signs are trustworthy?
- Which effects are real?
p-values fluctuate wildly across samples.
Bayesian Regression
stan_glm
family: gaussian [identity]
formula: y ~ .
observations: 30
predictors: 11
------
Median MAD_SD
(Intercept) -0.05 0.37
x1 0.44 0.80
x2 0.63 0.75
x3 0.28 0.77
x4 0.11 0.80
x5 0.18 0.72
x6 0.05 0.70
x7 -0.79 0.72
x8 0.63 0.66
x9 -0.32 0.79
x10 0.83 0.82
Auxiliary parameter(s):
Median MAD_SD
sigma 1.97 0.29
------
* For help interpreting the printed output see ?print.stanreg
* For info on the priors used see ?prior_summary.stanregLet’s have a look
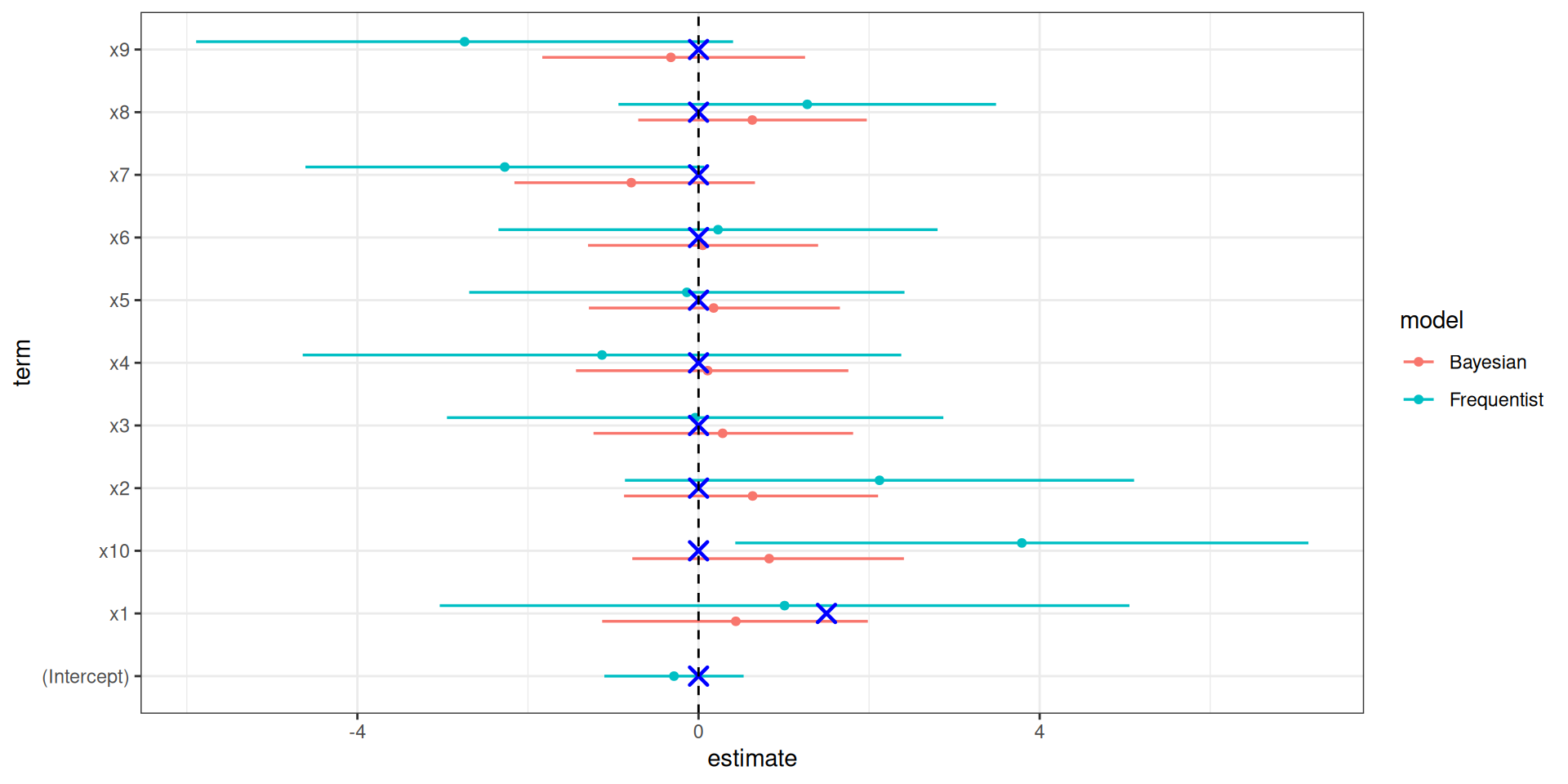
model estimates and ground truth.
What the Prior Does
The prior shrinks implausible coefficients toward zero.
Not aggressively.
Just enough to stabilize weakly identified directions.
This is called:
- regularization
- shrinkage
- partial pooling of uncertainty
Bias-Variance Tradeoff
Frequentist OLS emphasizes unbiasedness.
But unbiased estimators can have enormous variance.
Bayesian regression accepts:
- tiny bias
- dramatically lower variance
This often improves:
- prediction
- calibration
- scientific interpretation
The Deep Point
OLS treats the model as fixed truth.
Bayesian workflow treats models as uncertain approximations.
This distinction is profound.
Posterior Interpretation
Frequentist confidence interval:
Does NOT mean: “There is a 95% probability the parameter lies here.”
Bayesian posterior interval:
Literally means: “Given model and data, there is 95% posterior probability the parameter lies here.”
Weak Identification
The Bayesian posterior honestly expresses:
- uncertainty
- partial identifiability
- lack of information
Sometimes the correct scientific answer is:
“We do not know very much.”
OLS often hides this instability behind noisy point estimates.
Posterior Predictive Thinking
Bayesian models naturally support:
- posterior predictive checks
- hierarchical models
- measurement error
- causal modeling
- uncertainty propagation
This enables model criticism rather than blind estimation.
A More Extreme Failure
Increase:
- predictors from 10 to 20
- correlation from 0.9 to 0.95
OLS becomes nearly meaningless.
Coefficients:
- explode
- reverse sign
- become sample-dependent noise
Bayesian regularization still produces stable inference.
The Core Mechanism
Frequentist OLS:
\(hat{β}\) =arg min RSS
Bayesian regression:
\[ p(\beta \mid y) \propto p(y \mid \beta)p(\beta) \]
The prior changes the geometry of inference.
This is the key idea.
Final Takeaway
Bayesian regression matters because:
- real models are weakly identified
- finite samples are noisy
- predictors are correlated
- unconstrained likelihoods become pathological
Priors repair inferential geometry.
Final Thought
The Bayesian question is not:
“What coefficient minimizes error?”
The Bayesian question is:
“What parameter values remain plausible after combining data with scientific structure?”
That is usually the more meaningful scientific question.
References
Gelman, A., et al. Bayesian Data Analysis McElreath, R. Statistical Rethinking Vehtari, A., Gelman, A., Gabry, J. (2017) “Practical Bayesian model evaluation using leave-one-out cross-validation” Hastie, Tibshirani, Friedman. Elements of Statistical Learning