14.2 Case session 4: “I want to see this association for myself”
At AalboR Statistical Hospital, a new exercise-based cardiac assessment protocol has recently been introduced following an initial data review suggesting that patients with lower max heart rate are more likely to have underlying heart disease. Based on this, some clinicians have started using the max heart rate during exercise as a quick indicator when evaluating chest pain patients.
However, during a recent internal meeting, a cardiologist raises a concern:
“I’m not convinced this applies to our patients. Especially those who develop chest pain during exercise — their heart rate response might behave differently. If that’s true, we could be misinterpreting results in a subgroup of patients. I want to see this association for myself”
You are asked to explore the hospital’s patient data to assess whether the relationship between Age and max heart rate — and the interpretation of max heart rate more generally — appears consistent across patients, or whether it differs depending on exercise-induced angina, sex, or other patient characteristics.
You are tasked with the decision: Should this new assessment approach be used broadly, or are there patient groups where it may be misleading?
14.3 Reading Task: Why Visualize Data?
In medicine, pharmaceuticals, and healthcare, data is everywhere — patient records, clinical trials, drug efficacy studies, hospital operations, and more. But raw numbers alone don’t tell the full story. Data visualization turns complex information into clear, actionable insights which effectively aids you (and your future colleagues) make faster, smarter decisions.
Which of these are easiest to draw information from:
x
y
0.0000000
0.0
0.3306940
3.2
0.6613879
6.1
0.9920819
8.4
1.3227759
9.7
1.6534698
10.0
1.9841638
9.2
2.3148577
7.4
2.6455517
4.8
2.9762457
1.6
3.3069396
-1.6
3.6376336
-4.8
3.9683276
-7.4
4.2990215
-9.2
4.6297155
-10.0
4.9604095
-9.7
5.2911034
-8.4
5.6217974
-6.1
5.9524913
-3.2
6.2831853
0.0
Good visualizations help you:
Spot patterns (e.g., a sudden spike in adverse drug reactions)
Communicate findings (e.g., convincing a hospital board to adopt a new protocol)
Avoid mistakes (e.g., misreading a critical lab value in a dense table)
A dashboard with a red alert trendline for rising post-op infections will get noticed faster than a 10-page report. Example: A heatmap showing regional disease outbreaks helps public health teams act quickly.
Improve access to information
Text: “The Phase III trial showed a 12% reduction in mortality (p<0.05) with Drug X vs. placebo, but subgroup analysis revealed no benefit in patients over 65.” Visual: A forest plot or bar chart shows this in seconds—no PhD in stats required. Why it matters: Doctors, nurses, and executives don’t have time to parse dense tables.
Increase precision
Misreading a table could lead to: - Wrong doses prescribed. - Flawed trial conclusions (e.g., missing a safety signal).
A clear scatter plot or box plot reduces ambiguity.
Bolster credibility
Claim: “Our new drug reduces symptoms by 30%!” Without visualization: Skepticism (“Where’s the proof?”). With visualization: A Kaplan-Meier curve or before/after comparison lets stakeholders see the evidence. Real-world impact: Regulators and investors demand transparency—visuals provide it.
Summarise content
A single infographic can replace pages of text in: Patient education (e.g., “How this vaccine works”). Boardroom presentations (e.g., “Why we should expand this clinic”). Example: A Sankey diagram showing patient flow in a hospital highlights bottlenecks at a glance.
Data visualization isn’t just about “making things look nice”. It’s a critical skill for being able to evaluate any scientific claim. Through this class, we’ll dive into how to choose the right visualization for a given data structure and how to avoid common mistakes.
14.3.1 Discussion activity: Your experience with data visualization:
Where do you see data visualization “in the wild”?
What makes you trust a figure/graph? What could make you distrust it?
What’s one type of data you’ve seen in your studies/clinical rotations that was able to provide a lot of (valuable) information using a visualization?
14.4 The name of the game:
Do older patients have higher or lower max heart rate than younger patients? You probably already have an answer, but try to make your answer precise. What does the relationship between age and max heart rate look like? Is it positive? Negative? Linear? Nonlinear? Does the relationship vary by the presence of exercise-induced angina in the patient? How about by the sex? Let’s create visualizations that we can use to answer these questions.
14.5 The Cleveland Heart Disease data frame
To make the discussion easier, let’s define some terms (we use the definition from (1))
A variable is a quantity, quality, or property that you can measure.
A value is the state of a variable when you measure it. The value of a variable may change from measurement to measurement.
An observation is a set of measurements made under similar conditions (you usually make all of the measurements in an observation at the same time and on the same object). An observation will contain several values, each associated with a different variable. We’ll sometimes refer to an observation as a data point.
Tabular data is a set of values, each associated with a variable and an observation. Tabular data is tidy if each value is placed in its own “cell”, each variable in its own column, and each observation in its own row.
In this context, a variable refers to an attribute of all the patients, and an observation refers to all the attributes of a single patient.
Load the data and type the name of the data frame in the console and R will print a preview of its contents.
Rows: 303 Columns: 15
── Column specification ────────────────────────────────────────────────
Delimiter: ","
chr (3): ChestPain, Thal, HD
dbl (12): ...1, Age, Sex, RestBP, Chol, Fbs, RestECG, MaxHR, ExAng, ...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
ExAng: a penguin’s species (Adelie, Chinstrap, or Gentoo).
Age: length of a penguin’s flipper, in millimeters.
MaxHR: body mass of a penguin, in grams.
14.6 Ultimate goal
Our ultimate goal in this chapter is to recreate the following visualization displaying the relationship between flipper lengths and body masses of these penguins, taking into consideration the species of the penguin.
14.7 Hallo {ggplot2}
R has several systems for making graphs, but ggplot2 is one of the most elegant and most versatile. ggplot2 implements the grammar of graphics, a coherent system for describing and building graphs. With ggplot2, you can do more and faster by learning one system and applying it in many places.
ggplot2 is an implementation of the “Grammar of Graphics” (“gg”). This is a powerful approach to creating plots because it provides a set of structured rules (a “grammar”) that allow you to expressively describe components (or “layers”) of a graph. Since you are able to describe the components, it is easier to then implement those “descriptions” in creating a graph. According to (2), there are at least four aspects to using ggplot2 that relate to its “grammar”:
Aesthetics, aes(): How data are mapped to the plot, including what data are put on the x and y axes, and/or whether to use a colour for a variable.
Geometries, geom_ functions: Visual representation of the data, as a layer. This tells ggplot2 how the aesthetics should be visualized, including whether they should be shown as points, lines, boxes, bins, or bars.
Scales, scale_ functions: Controls the visual properties of the geom_ layers. Can be used to modify the appearance of the axes, to change the colour of dots from, e.g., red to blue, or to use a different colour palette entirely.
Themes, theme_ functions or theme(): Directly controls all other aspects of the plot, such as the size, font, and angle of axis text, and the thickness or colour of the axis lines.
There is a massive amount of features in ggplot2. Thankfully, ggplot2 was specifically designed to make it easy to find and use its functions and settings using tab auto-completion. To demonstrate this feature, try typing out geom_ and you’ll start seeing a menu pop-up with a list of functions that start with geom_. You can then use the arrow keys to move up and down the list and then hit either Enter or Tab to select the function. You can use this with scale_ or the options inside theme(), for instance try typing out theme(axis. to see all options for the axis a list of theme settings related to the axis will pop up.
14.8 Plot one continuous variable
Since low max heart rate has been proposed as a risk factor for heart disease, let’s check out the distribution of max heart rate among the patients. There are two good geoms for examining distributions for continuous variables: geom_density() and geom_histogram(). Before we can make a plot, we need to tell ggplot2 what data we are using and which variable to put in which axis or dimension. For that we use the ggplot() function with the aes() function used inside of it.
docs/session4.R
hd_data|>ggplot(aes(x =MaxHR))
Run this code by using Ctrl-EnterCtrl-Enter. You’ll get a blank plot. That’s because we haven’t told ggplot2 what kind of plot we want to make, which needs a geom_ function.
We’ll start with creating a histogram, which is a useful way of visualizing the distribution of a continuous variable. We do that with geom_histogram(), but you can easily replace the code with geom_density() to make a density plot. Note that it is good practice to always create a new line after the +.
docs/session4.R
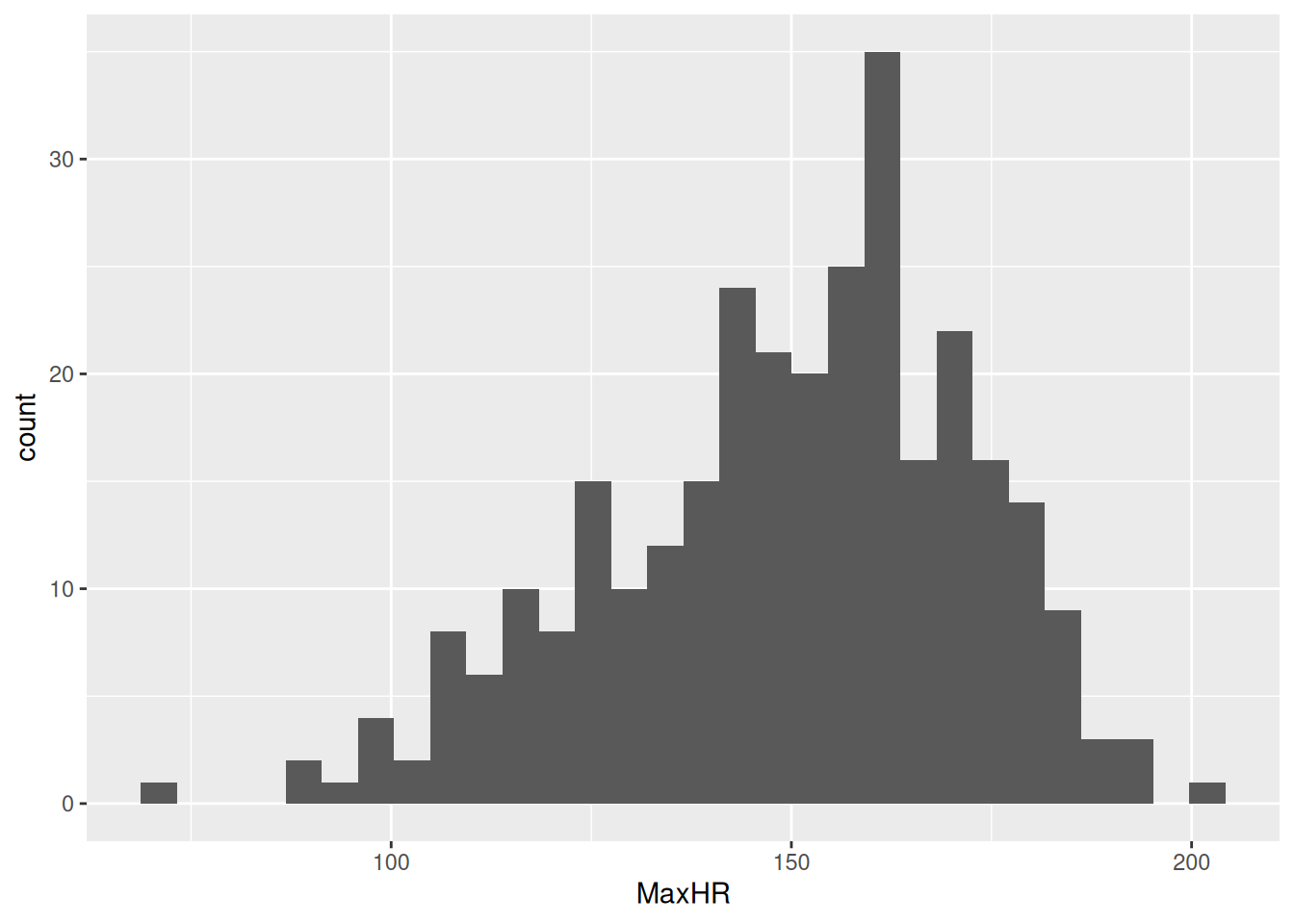
ggplot(hd_data, aes(x =MaxHR))+geom_histogram()
`stat_bin()` using `bins = 30`. Pick better value `binwidth`.
Tip
If your data has missing values, ggplot2 gives us a warning about dropping the missing values. Like many functions in R, especially the summary statistic functions like mean(), you can set the argument na.rm = TRUE in the geom_histogram() function, as well as in other geom_* functions.
Our plot shows that, for the most part, there is a even distribution with MaxHR.
14.9🧑💻 Exercise: Rotate the axis of a plot
For several reasons, switching the x and y axis can be very helpful for some data visualization purposes. But how do we define x and y in the previous plot - we only set the x-variable!?
Luckily, ggplot2 has a need function for this purpose, named coord_flip(). Try flipping the coordinates of the histogram of the max heart rate.
Click for the solution. Only click if you are struggling instead of using Chat models.
```{r solution-discrete-variables}#| eval: false#| code-fold: true#| code-summary: '**Click for the solution**. Only click if you are struggling instead of using Chat models.'# This is a potential solutionhd_data |>ggplot(hd_data, aes(x = MaxHR)) +geom_histogram()coord_flip()```
14.10 The box plot
We can see many things from the histogram:
The distribution looks approximately normal
The mean is somewhere around 150 BPM
Most data is between 100-200 BPM
From the looks of it, there might be one or two outliers in our dataset.
But can we help the reader identify these information using data visualization? Yes - yes, we can.
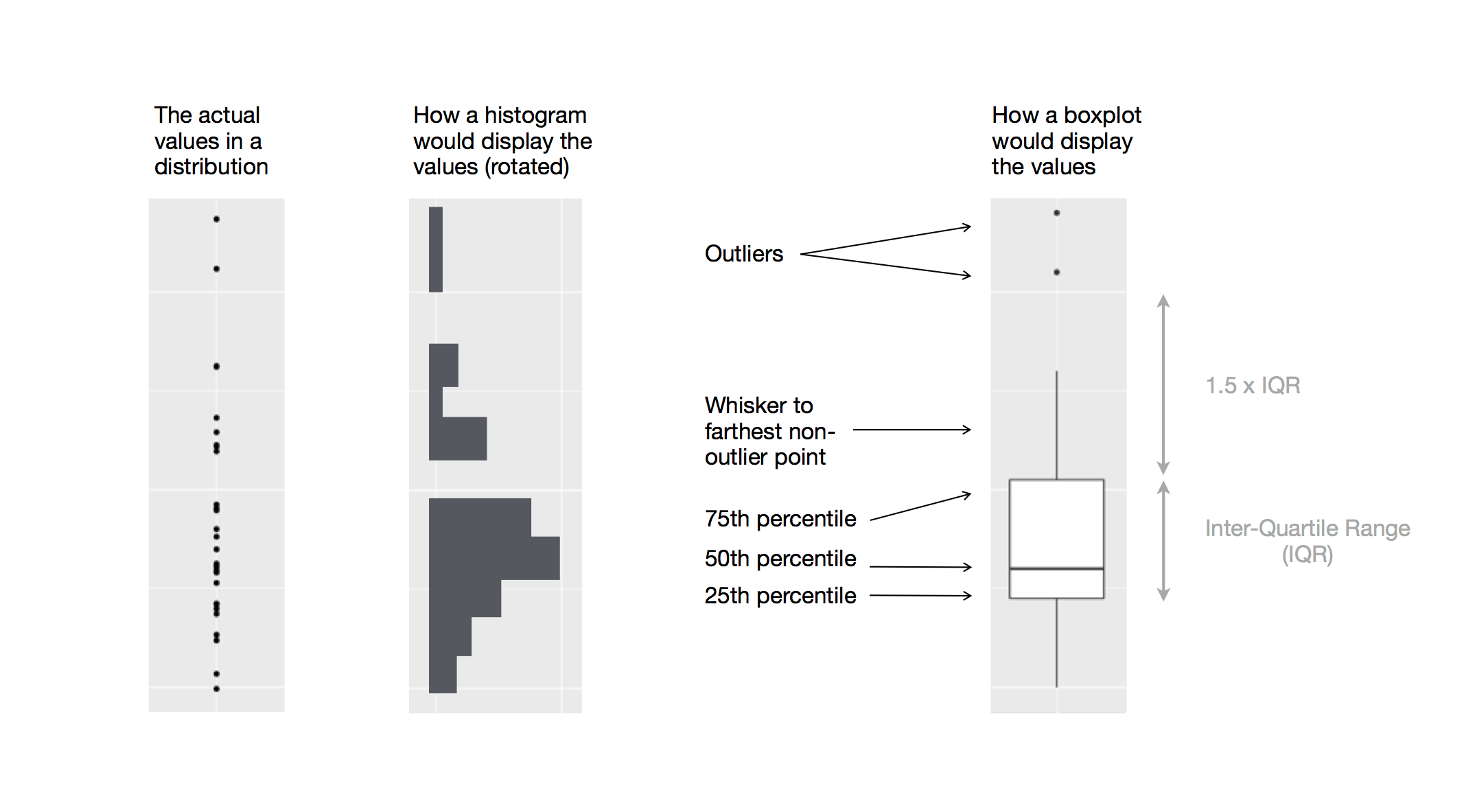
Take a close look at the humble boxplot, also known as the box-and-whisker plot:
Figure 14.1: Diagram depicting how a boxplot is created.
This figure is much better at showing the mean, IQR, and outliers (defined as > 1.5 IQR away from the 1st and 3rd quantiles). However, it leaves out the information on count (how msuch data?) and spikes (any values particularly popular?)
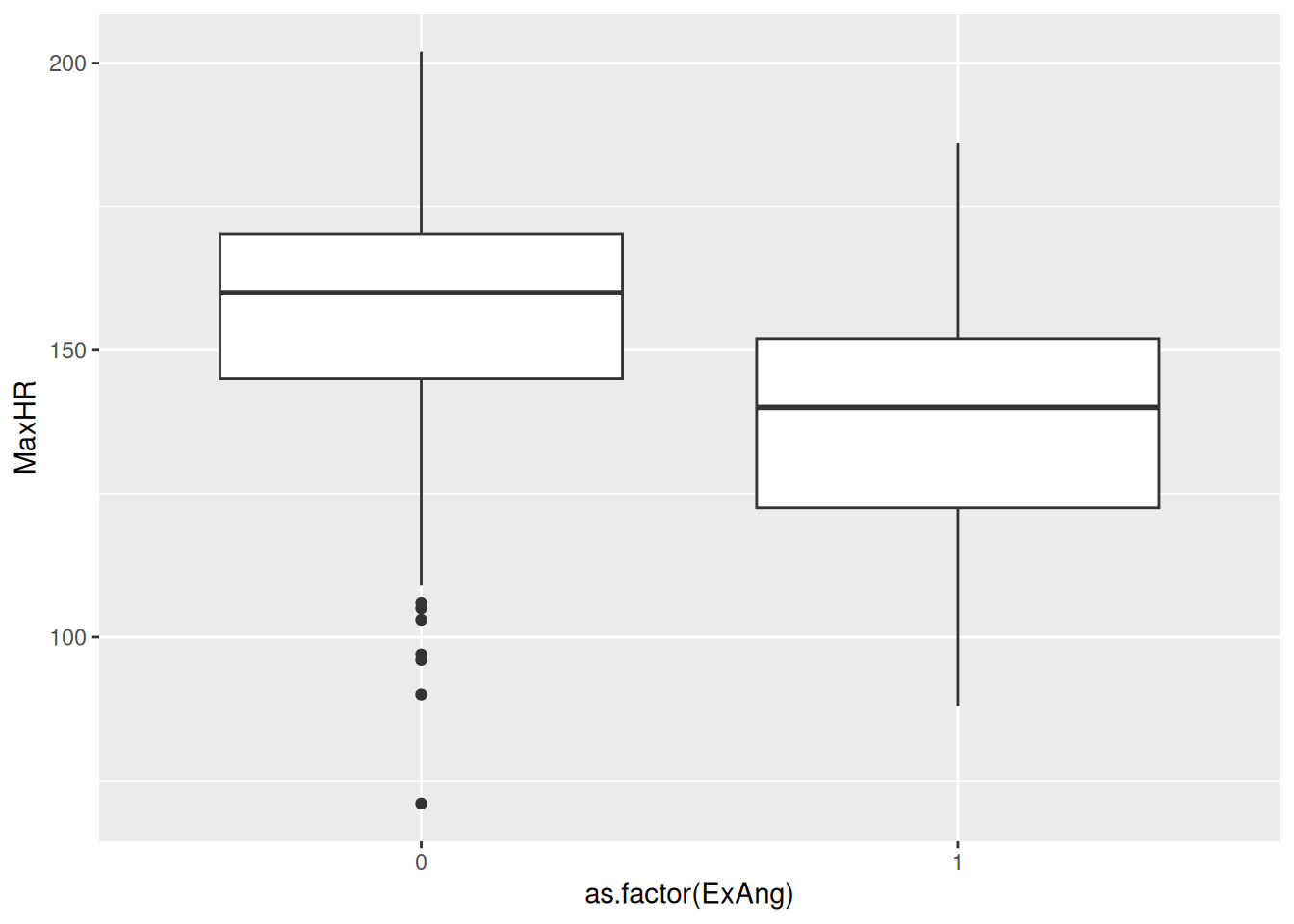
It is a very popular plot for comparing continuous variables between two groups. This is useful to us as well, so let’s try plotting this stratified for patients with(out) exercise-induced angesia
docs/session4.R
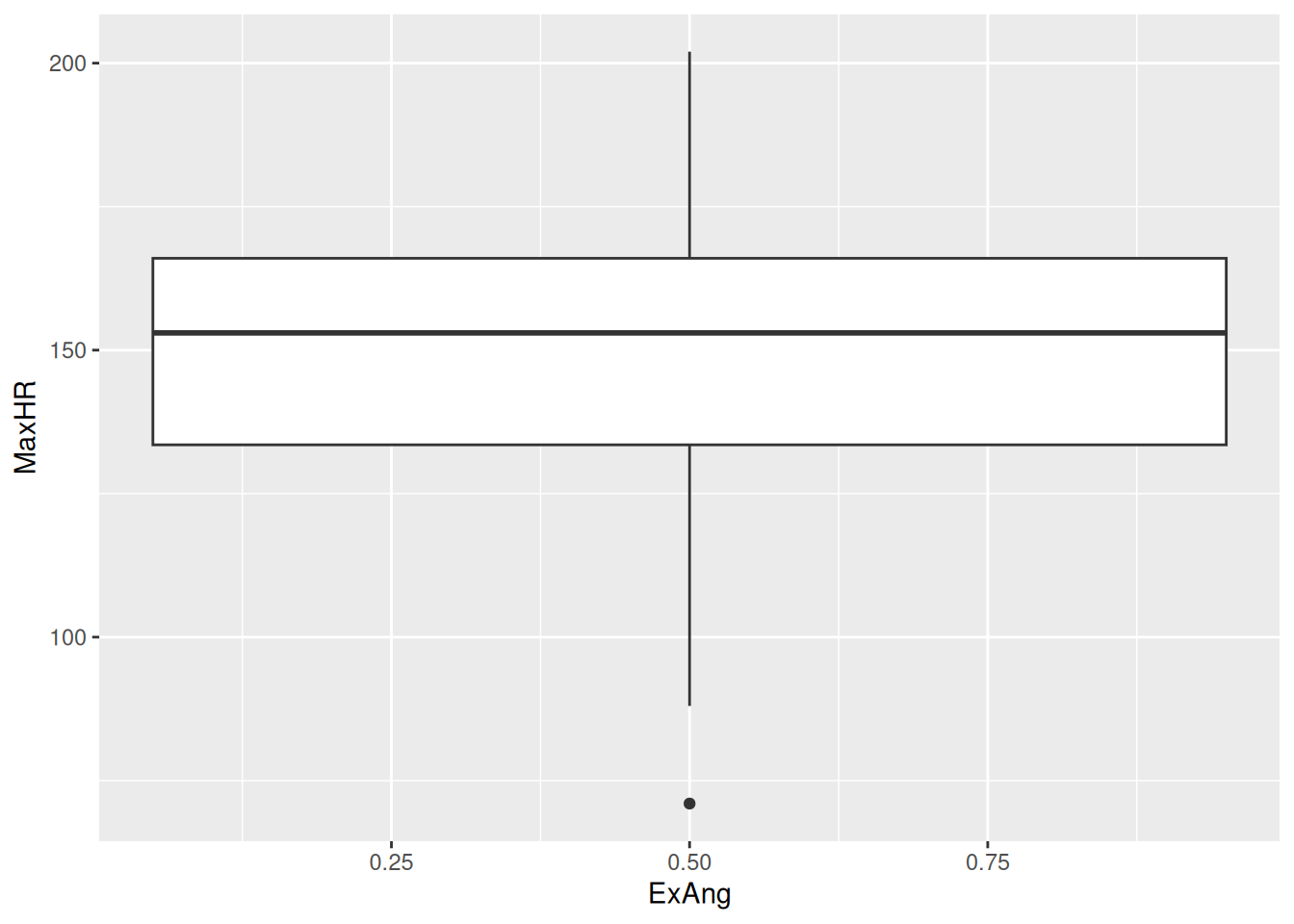
hd_data|>ggplot(aes(x =ExAng, y =MaxHR))+geom_boxplot()
Warning: Orientation is not uniquely specified when both the x and y aesthetics
are continuous. Picking default orientation 'x'.
Warning: Continuous x aesthetic
ℹ did you forget `aes(group = ...)`?
Wait a minute… We still only have one box plot and the value is at 0.5 - but when we inspect hd_data$ExAng or View(hd_data$), all values are 0 or 1?!
The problem, we realise, is the type - it’s numeric (or dbl for double precision floating-point data type). We actually consider it a factor indicating either yes/no. Let’s change the type as a factor using the factor function to correct this mistake.
docs/session4.R
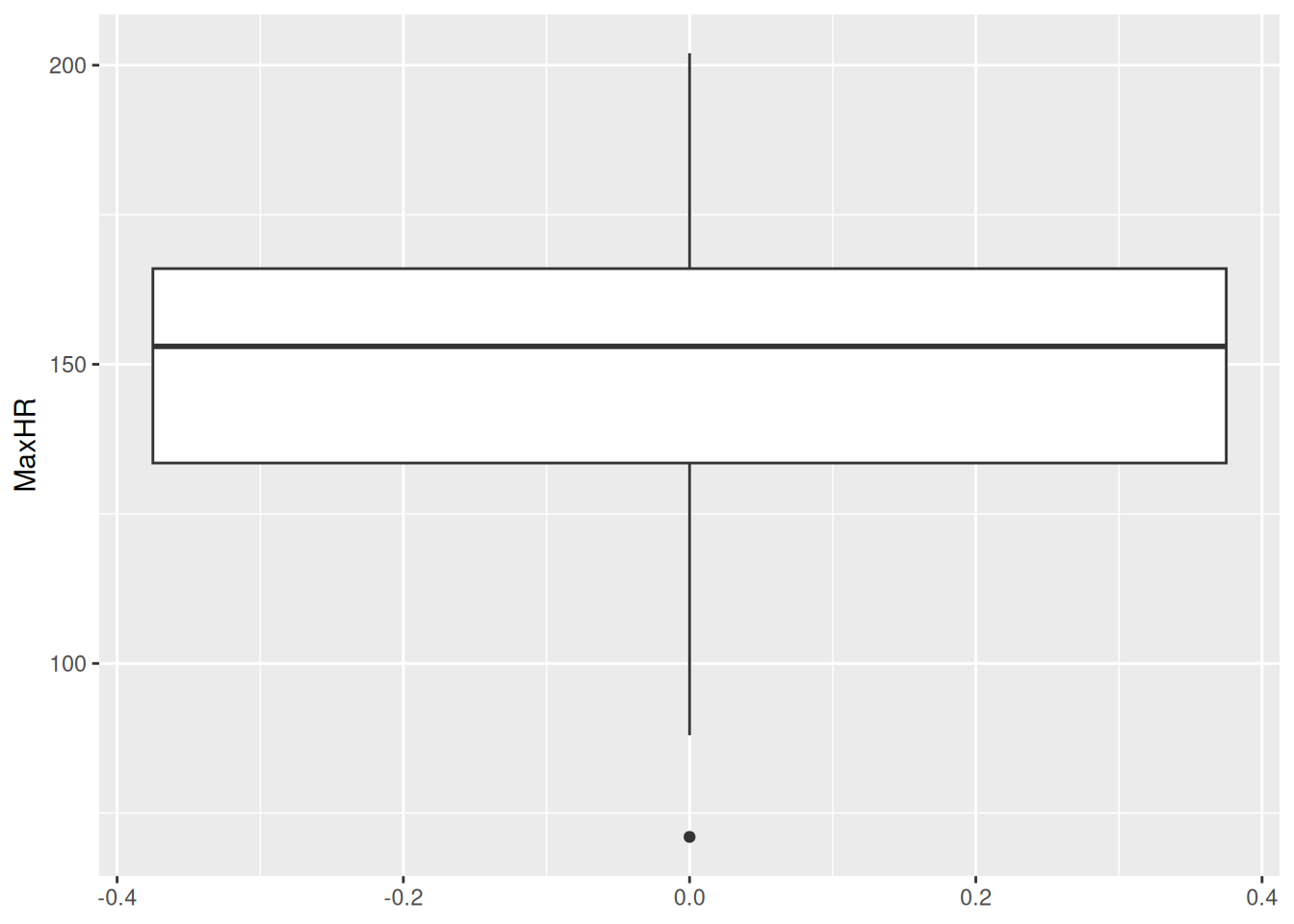
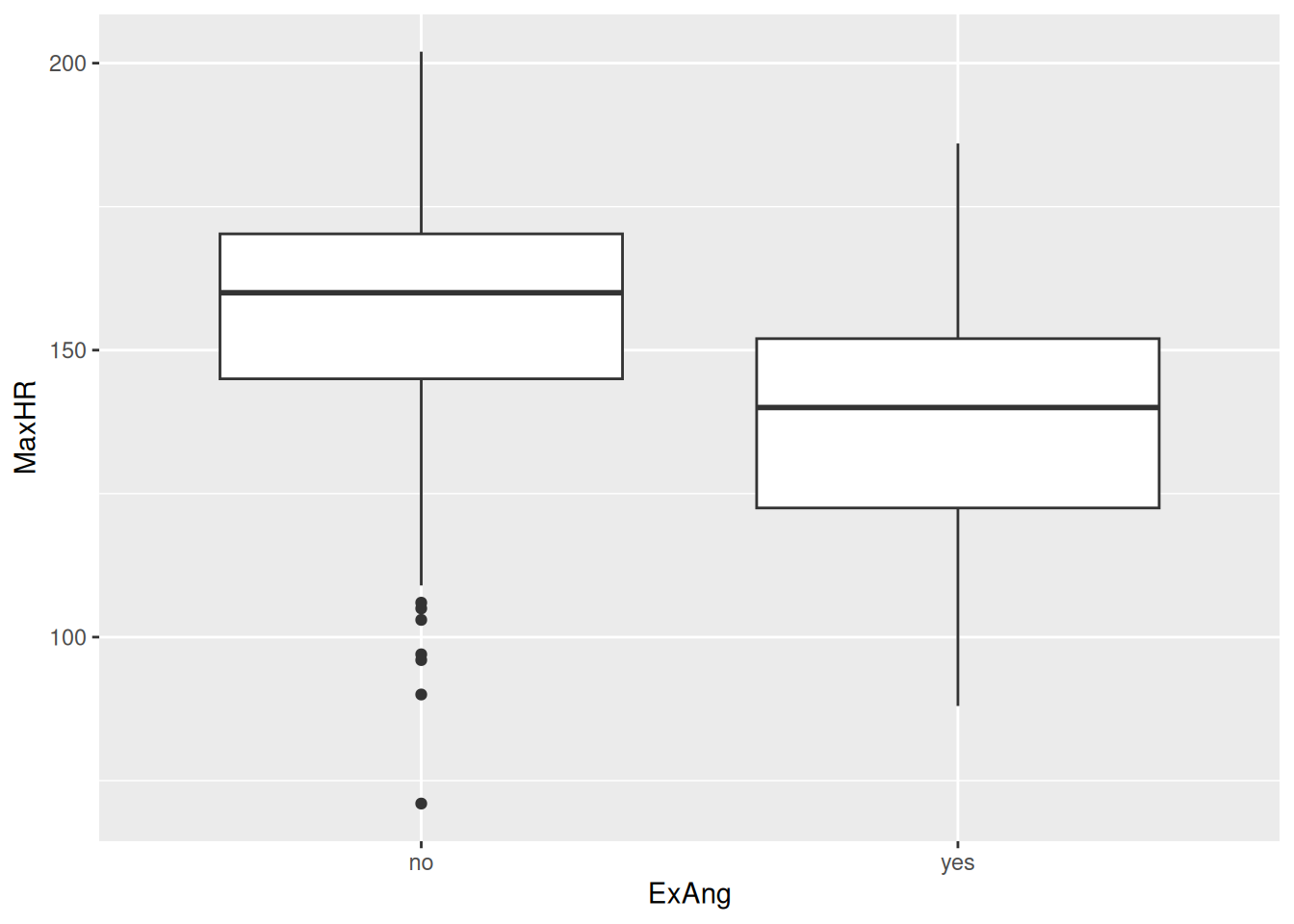
hd_data$ExAng<-factor(hd_data$ExAng, levels =c(0, 1), labels =c("no", "yes"))hd_data|>ggplot(aes(x =ExAng, y =MaxHR))+geom_boxplot()
Aha! It works. We now see the no/yes in the x-axis.
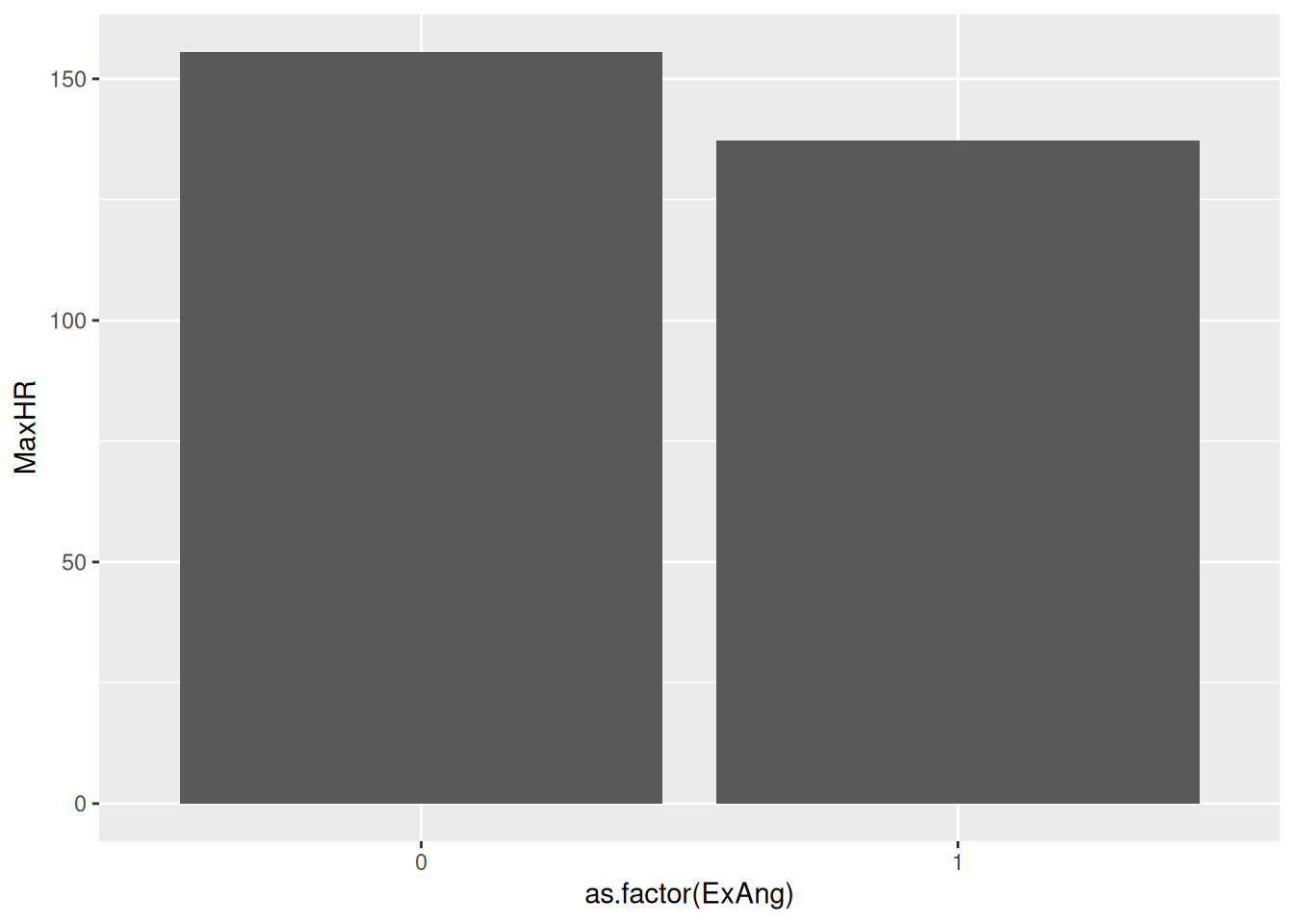
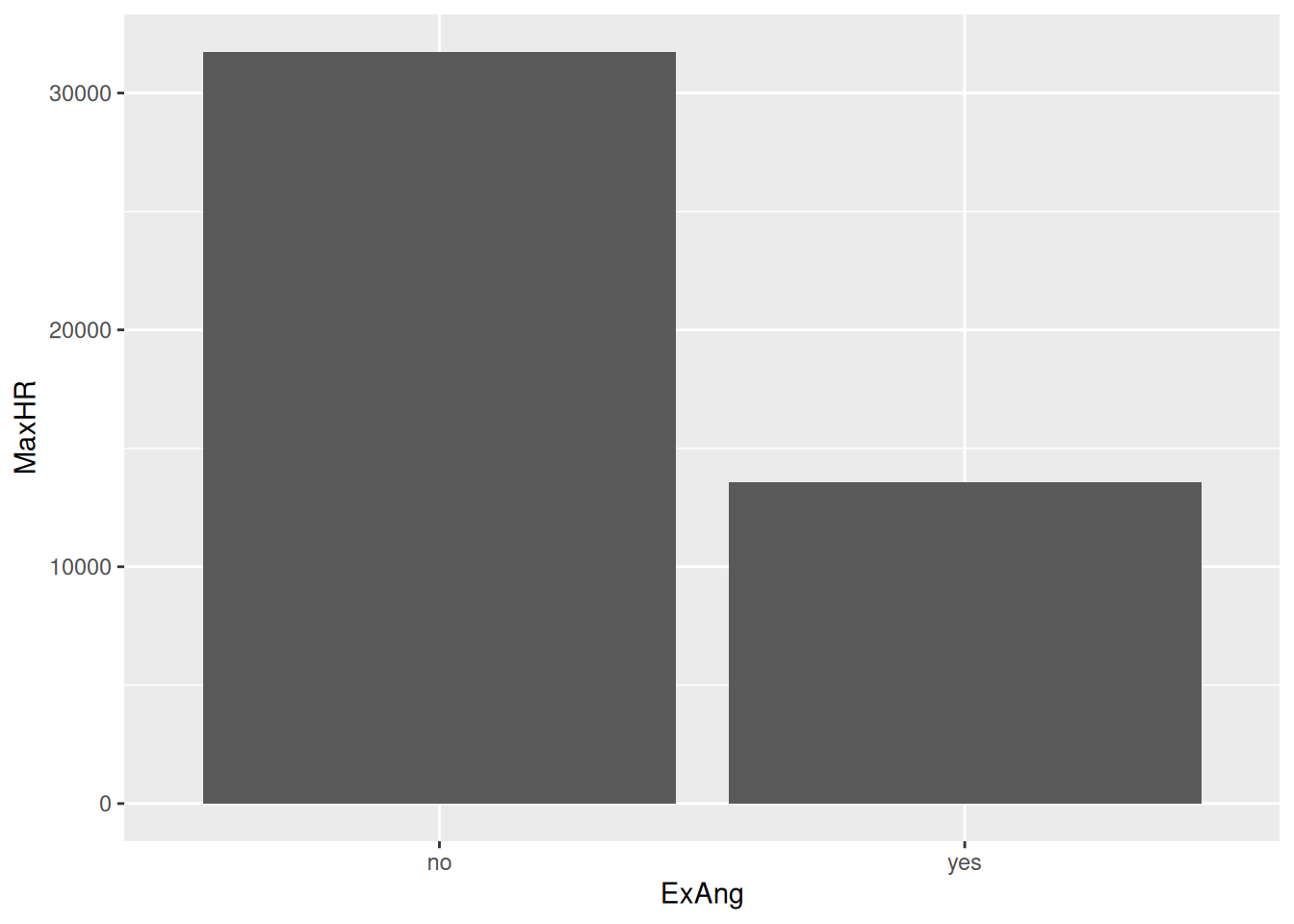
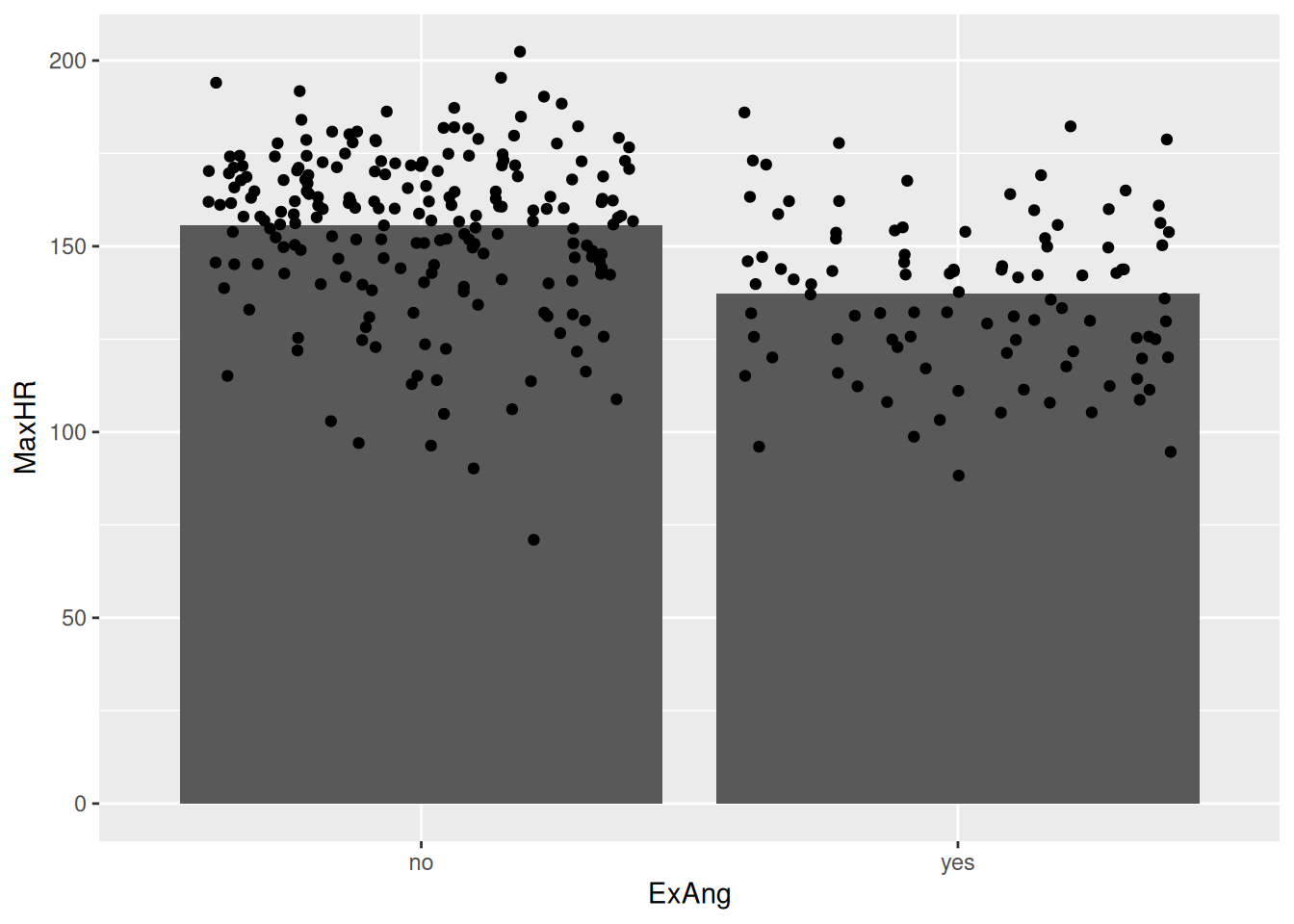
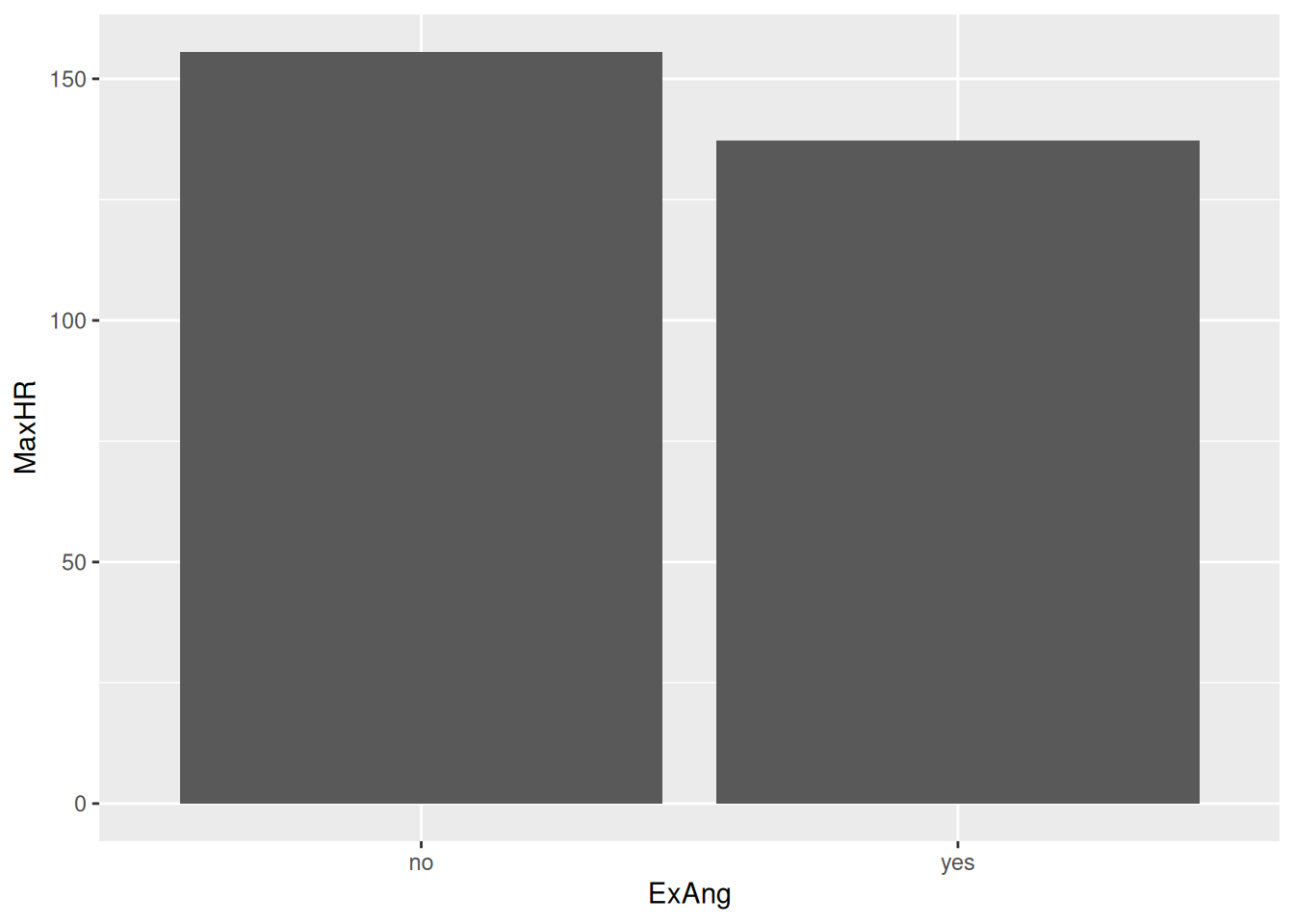
Hmm… I’ve never seen a human being with a max heart rate of +30.000 - this must be a mistake!
It turns out that the geom_col takes the sum of all observations. We wanted the mean!
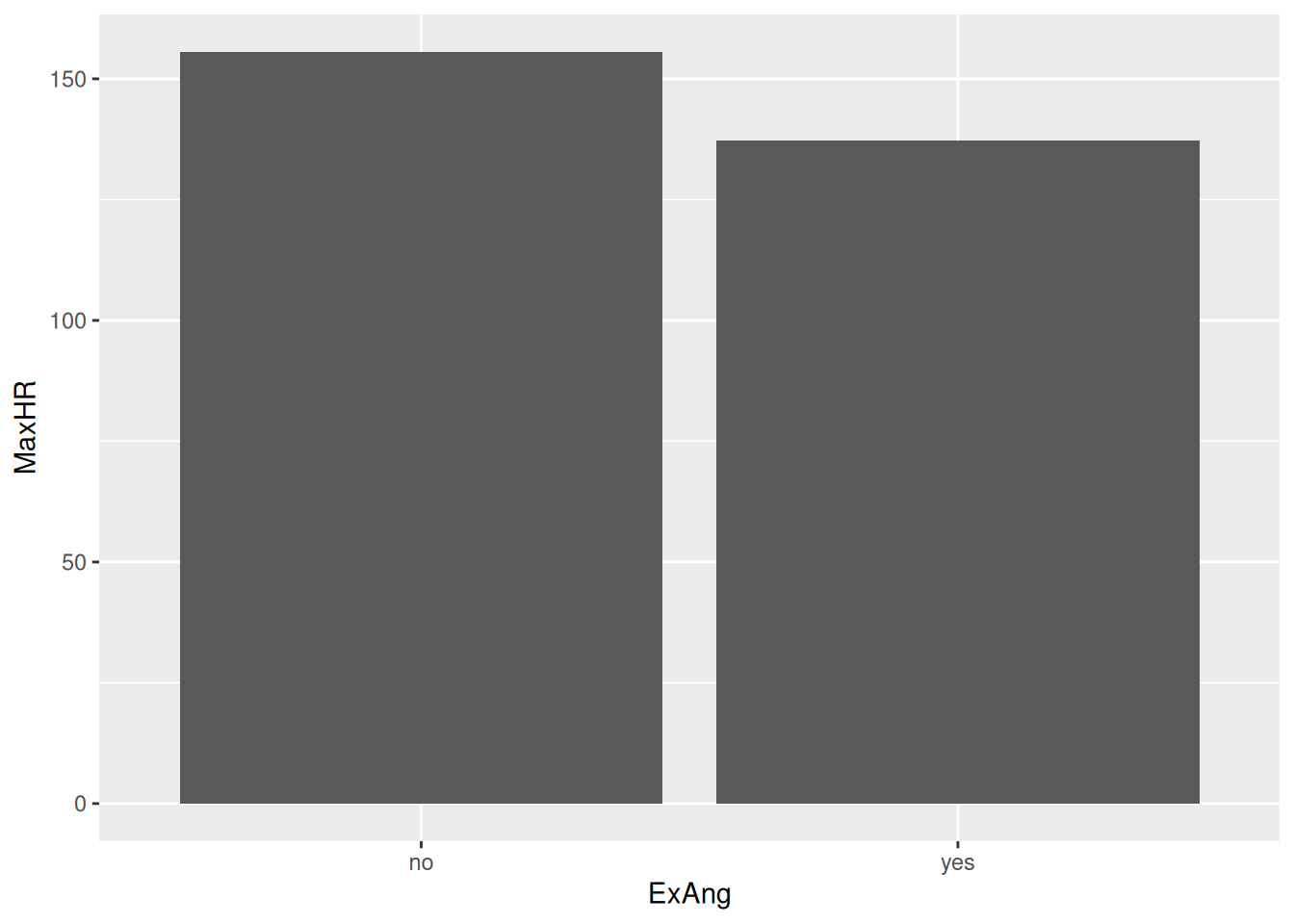
hd_data|>ggplot(ggplot2::aes(ExAng, MaxHR))+stat_summary(geom ="col", fun =mean)
This looks much better!
14.12📖 Reading task: Be careful with certain plots
NoteInstructor note
For this section on the bar-with-standard-error plots, make sure to go over and emphasize the problems and major flaws with using this type of plot. Really try to reinforce the concept here.
Time: ~5 minutes
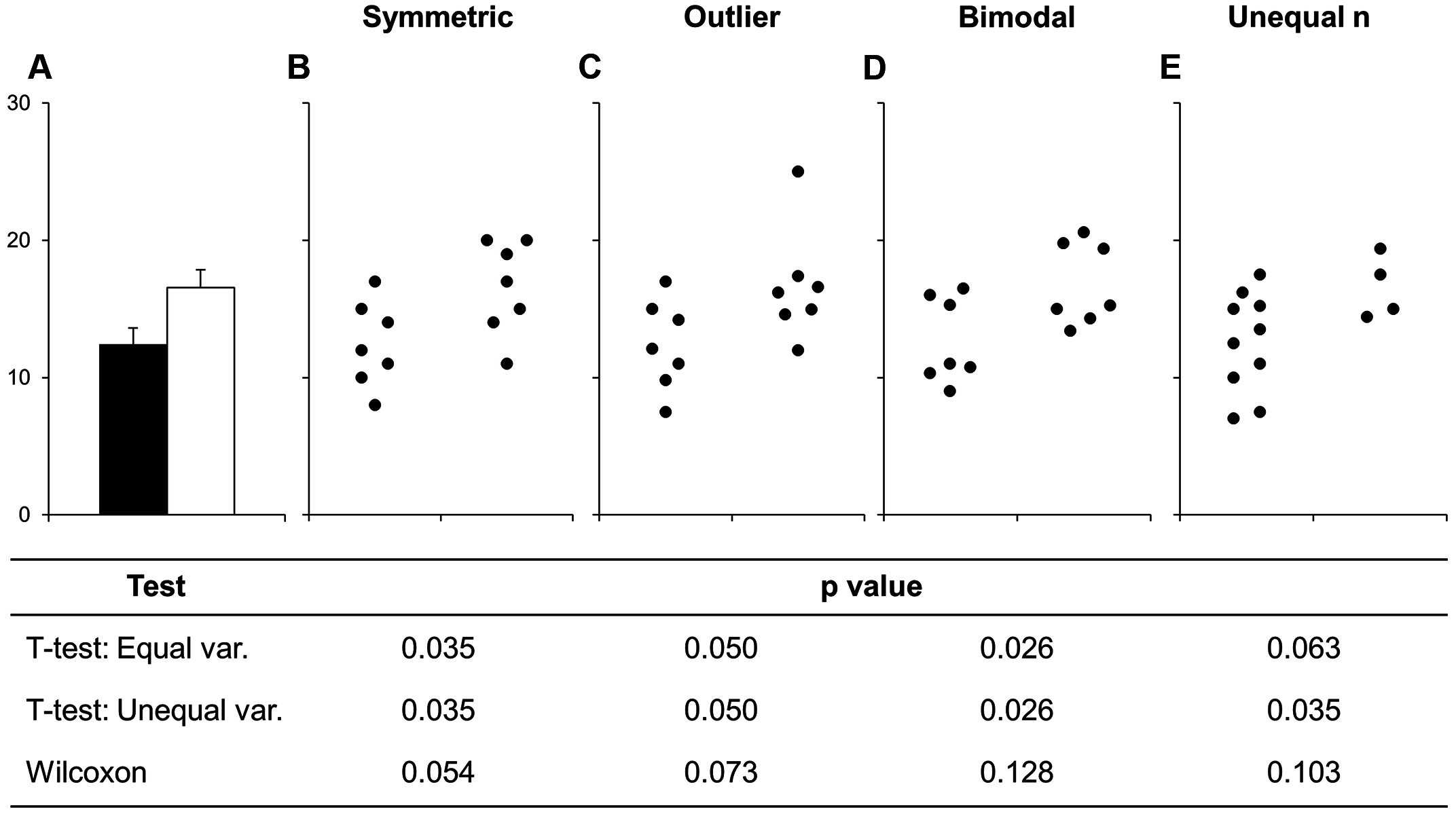
Before continuing with plotting, let’s take a minute to talk about a commonly used barplots with mean and error bars. In all cases, barplots should only be used for discrete (categorical) data where you want to show counts or proportions. As a general rule, they should not be used for continuous data. This is because the commonly used “bar plot of means with error bars” actually hides the underlying distribution of the data. To have a better explanation of this, you can read the article on why to avoid barplots after the workshop. The image below was taken from that paper, and briefly demonstrates why this plot type is not useful.
Figure 14.2: Bars deceive what the data actually look like. Image sourced from a PLoS Biology article.
If you do want to create a barplot, you’ll quickly find out that it is actually quite hard to do in ggplot2. The reason it is difficult to create in ggplot2 is by design: it’s a bad plot to use, so use something else.
Figure 14.3: Barplots hide interesting results. Artwork by @allison_horst.
hd_data|>ggplot(ggplot2::aes(ExAng, MaxHR))+stat_summary(geom ="col", fun =mean)+geom_jitter()
It is also possible to compute error bars using ggplot2.
hd_data|>ggplot2::ggplot(ggplot2::aes(ExAng, MaxHR))+ggplot2::stat_summary(geom ="col", fun =mean)+ggplot2::stat_summary( fun.data ="mean_cl_boot", # The 95% confidence interval of the mean # "mean_cl_normal" # mean_sdl geom ="errorbar", width =.15)
Warning: Computation failed in `stat_summary()`.
Caused by error in `fun.data()`:
! The package "Hmisc" is required.
However, it’s much safer and better practice computing the standard deviation, standard error, or confidence interval using dplyr first. You’ll learn how to do this in a later class.
At least, consider adding the points too. It’s as simple as adding another ggplot-layer
14.13 The scatter plot
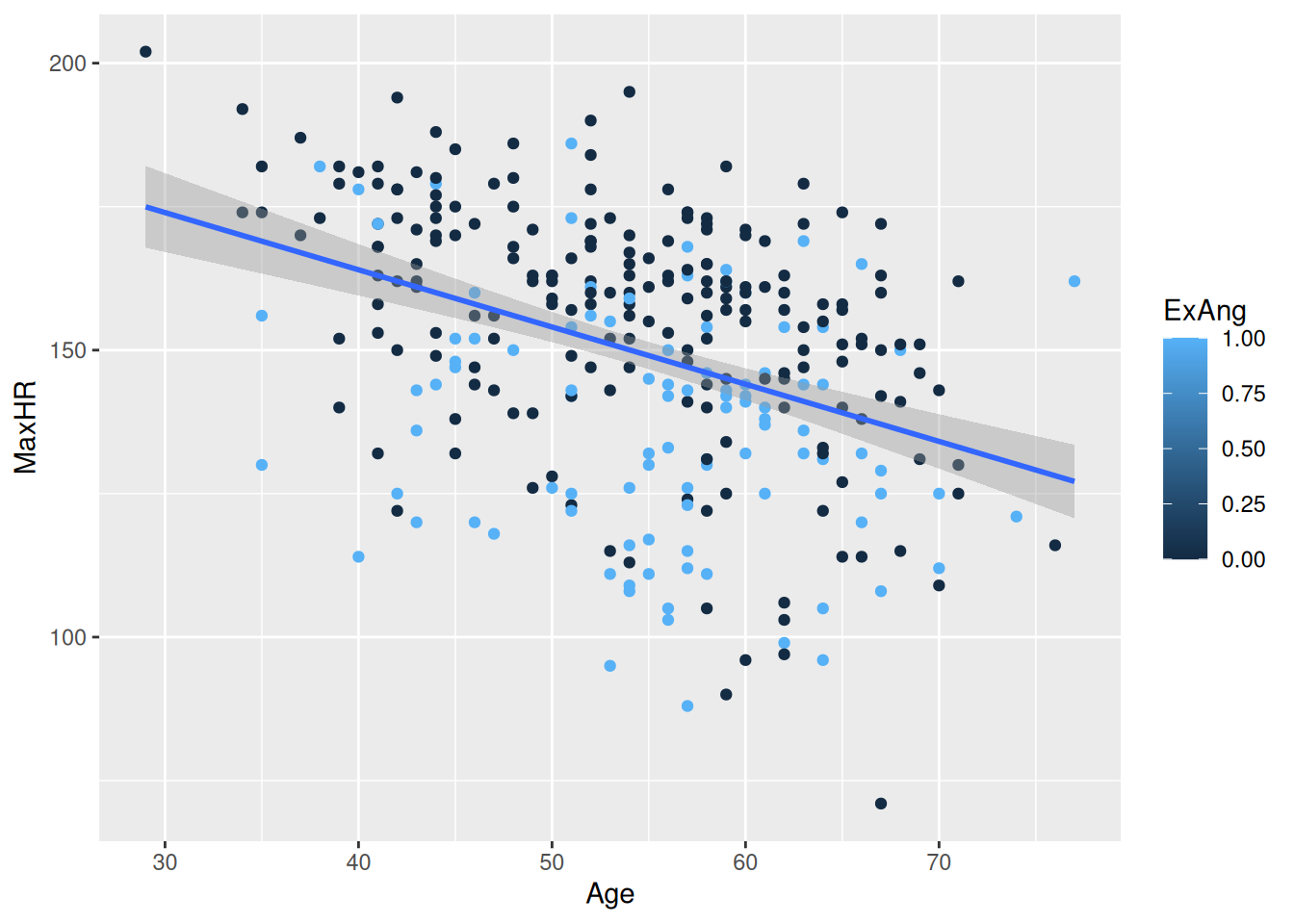
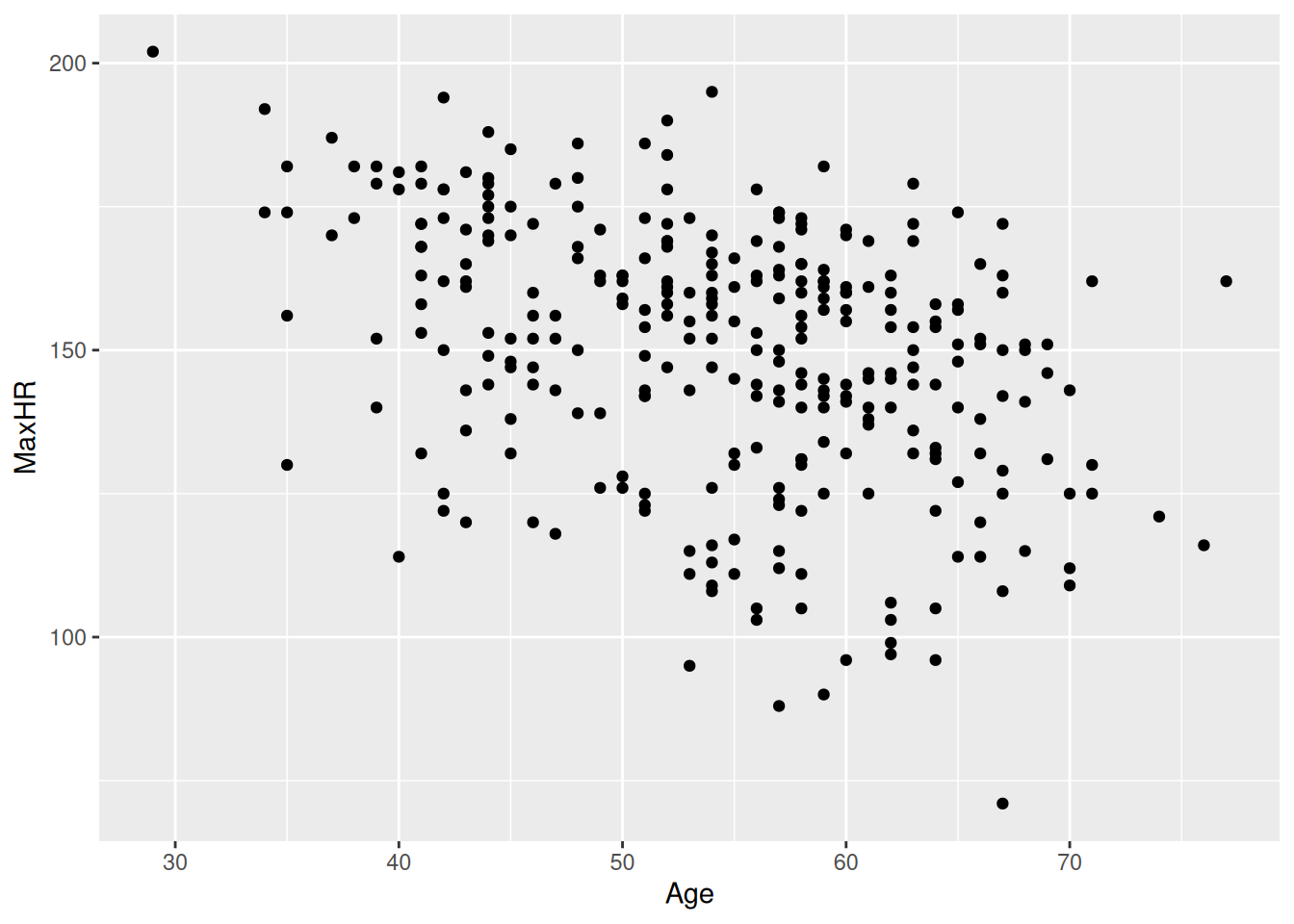
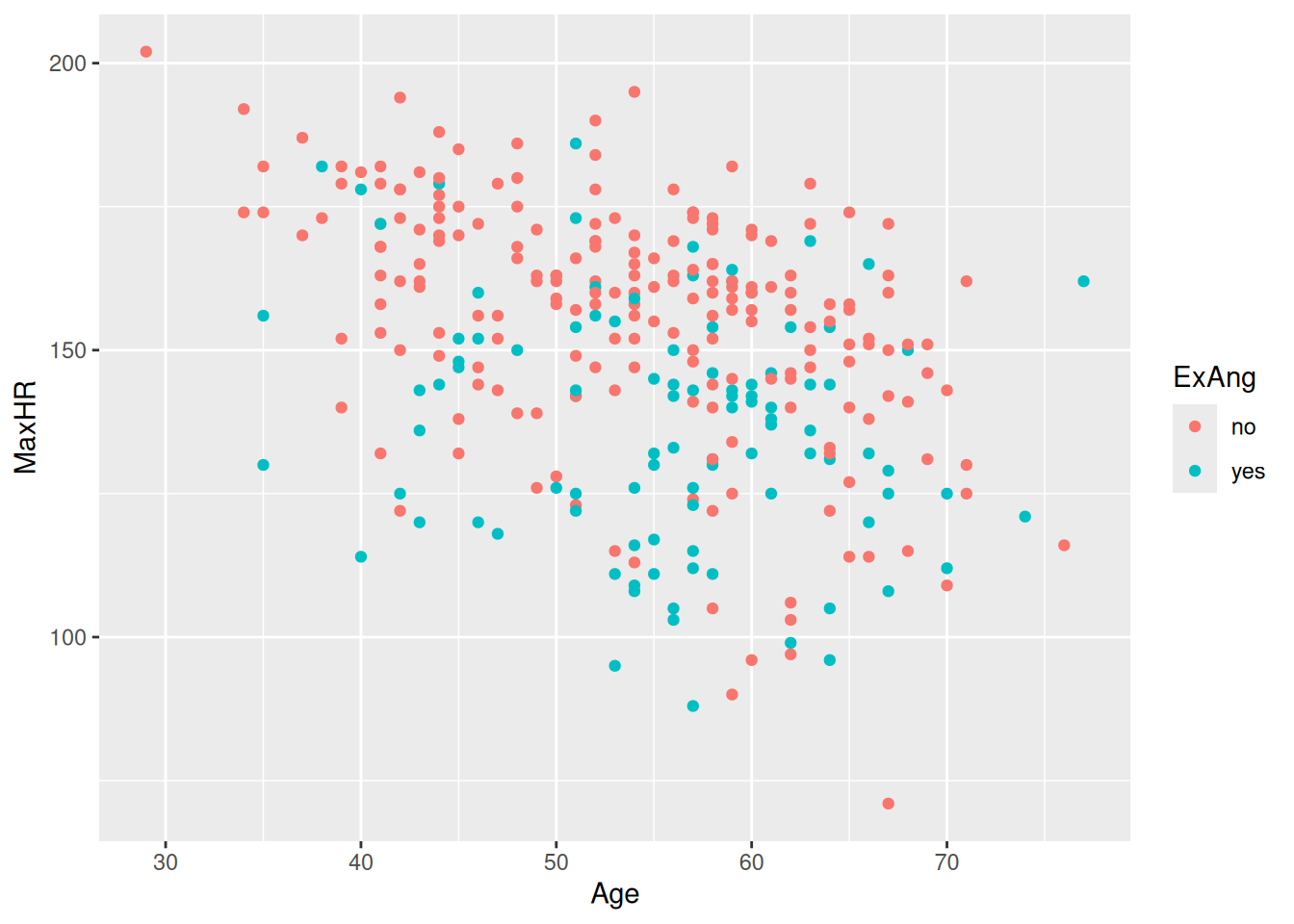
hd_data|>ggplot(aes(Age, MaxHR))+geom_point()
Let’s add color
hd_data|>ggplot(ggplot2::aes(Age, MaxHR, color =ExAng))+geom_point()
Do they follow similar trends?
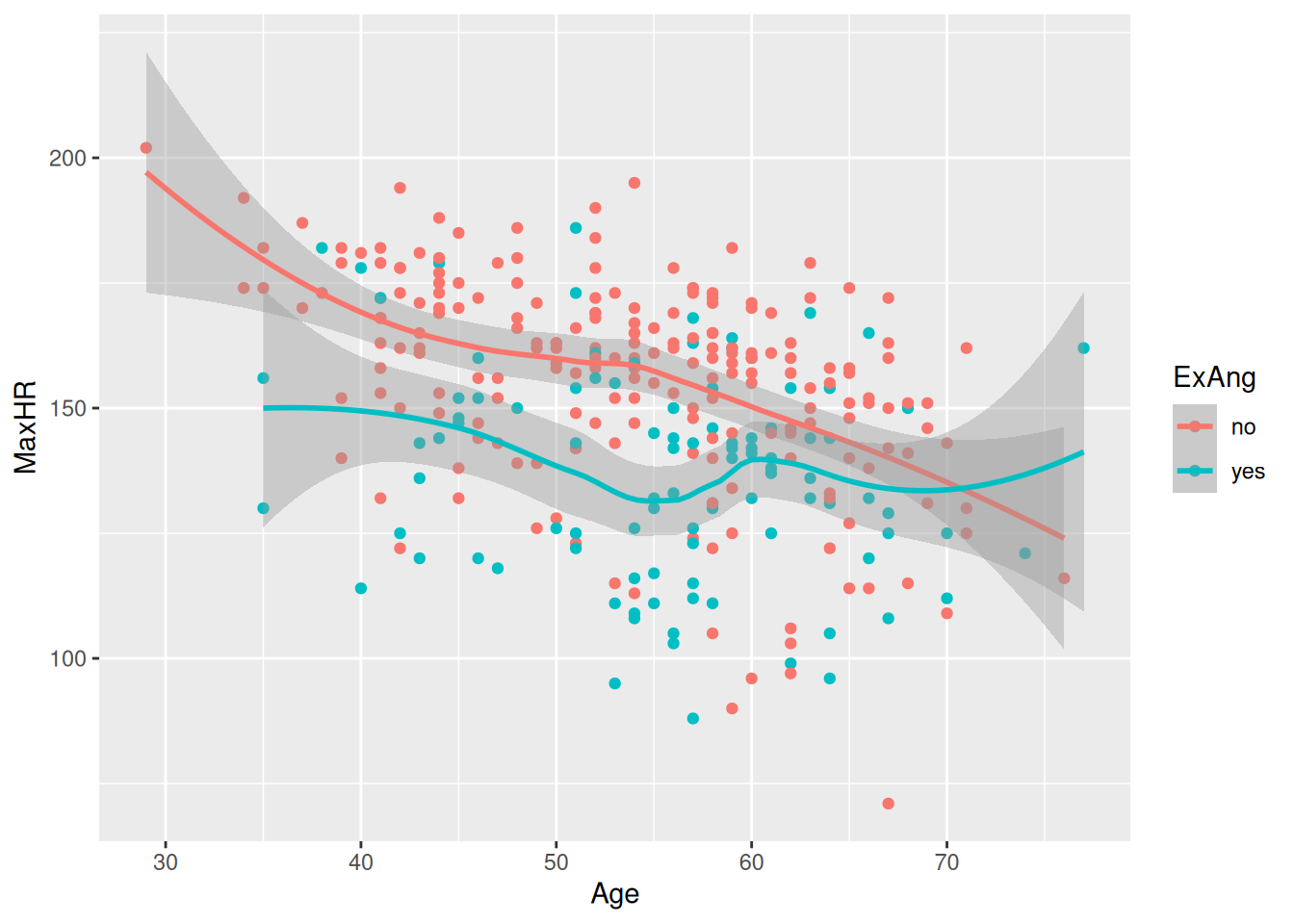
hd_data|>ggplot(ggplot2::aes(Age, MaxHR, color =ExAng))+geom_point()+geom_smooth()
`geom_smooth()` using method = 'loess' and formula = 'y ~ x'
14.14 Saving your plots
Once you’ve made a plot, you might want to get it out of R by saving it as an image that you can use elsewhere. That’s the job of ggsave(), which will save the plot most recently created to disk:
hd_data|>ggplot(ggplot2::aes(Age, MaxHR, color =ExAng))+geom_point()+geom_smooth()ggsave(filename ="subgroup-association.png")
This will save your plot to your working directory (which should be the root of your project folder, if you’re in your R-project (see session 1).
14.15 Even statistics fail at what data visualization makes obvious
Pharma: Accelerating drug approvals with clear trial data. Hospitals: Improving patient outcomes through better decision-making. Industry: Convincing stakeholders (from doctors to CEOs) with evidence.
Examples
Present clinical trial results to regulators (e.g., FDA, EMA) or investors.
Compare drug efficacy across demographics in pharma R&D.
Explain risks/benefits to non-experts (patients, policymakers, or even journalists).
A well-designed chart can mean the difference between confusion and clarity — between a rejected proposal and an approved drug.
Use the “Grammar of Graphics” approach together with the ggplot2 package within tidyverse to plot your data.
Prioritize plotting raw data instead of summaries whenever possible.
ggplot2 has 4 levels of grammar: aes() to say which data to plot and how, geom_ to set the kind of plot to use, scale_ to make the plot prettier, and theme() to control the specifics of the plot. We covered the aes() and geom_ layers.
Only use barplots for discrete values. If applying them on continuous variables, it hides the distribution of the data.
Use geom_point() to create a scatterplot of two continuous variables.
Use geom_smooth() to add a smoothing line to the scatterplot.
Use geom_bar() to create a barplot of discrete variables.
14.17📖 Reading task: Basic principles for creating graphs
(2) Making graphs in R is relatively easy compared to other programs and can be done with very little code. Because it takes a few lines of code to create multiple types of plots, it gives you some time to consider: why you are making them; whether the graph you’ve selected is the most appropriate for your data or results; and how you can design your graphs to be as accessible and understandable as possible.
To start, here are some tips for making a graph:
Whenever possible or reasonable, show raw data values rather than summaries (e.g. means).
Though commonly used in scientific papers, avoid barplots with means and error bars as they greatly misrepresent the data (we’ll cover why later).
Use colour to highlight and enhance your message, and make the plot visually appealing.
Use a colour-blind friendly palette to make the plot more accessible to others (more on this later too).
14.18 Plotting two continuous variables
There are many more types of “geoms” to use when plotting two variables. Your choice of which one to use depends on what you are trying to show or communicate, and the nature of the data. Usually, the variable that you “control or influence” (the independent variable) in an experimental setting goes on the x-axis, and the variable that “responds” (the dependent variable) goes on the y-axis.
For now, let’s focus on plotting continuous data, since our data has a lot of continuous data and often in research we work with more continuous than discrete variables. When you have two continuous variables, some geoms to use are:
geom_point(), which is used to create a standard scatterplot. Since it is so commonly used, we’ll use this one.
geom_hex(), which is used to replace geom_point() when your data are massive and creating points for each value takes too long to plot.
geom_smooth(), which applies a “regression-type” line to the data.
Let’s check out how BMI may influence the area under the curve for blood glucose after the meal using a point plot. The area under the curve of glucose is a measure of how much glucose is present in the blood over a fixed period of time. A higher area under the curve for glucose usually suggests that the body has a harder time handling glucose. But, like everything in biology, it’s more complex than that. But we won’t cover that complexity in this workshop.
Like with the previous plot we created using BMI, we’ll put BMI on the x axis in the aes() function, since we are assuming that BMI “causes” or contributes to higher glucose in the blood after a meal. Then we put the area under the curve for glucose (auc_pg) on the y axis, since it will be “responding to” or “caused by” BMI.
docs/learning.qmd
#ggplot(post_meal_data, aes(x = BMI, y = auc_pg)) +# geom_point()
Run this code chunk with Ctrl-EnterCtrl-Enter. You’ll see a scatterplot of BMI and the area under the curve for glucose. Notice how there is a bit of an increase in glucose as BMI increases? Because ggplot2 works in layers, we can add another layer to the plot by adding a + after the geom_point() function. Let’s add a smoothing line to the plot to see if there is a general trend between BMI and glucose by using geom_smooth().
Run this code chunk with Ctrl-EnterCtrl-Enter and we’ll see a scatterplot of age and the max heart rate with a smoothing line on top of the points. The colors represent the sub-groups: exercises-induced angesio (yes/no).
This makes a nice smoothing line through the data and gives us an idea of general trends or relationships between the two variables.
Wickham H, Çetinkaya-Rundel M, Grolemund G. R for data science [Internet]. 2nd ed. O’Reilly Media; 2023. Available from: https://r4ds.hadley.nz/
2.
Johnston L, Juel H, Lengger B, Witte D, Chatwin H, Christiansen M, et al. R-cubed: Guiding the overwhelmed scientist from random wrangling to reproducible research in r. Journal of Open Source Education [Internet]. 2021;4(44):122. Available from: https://doi.org/10.21105/jose.00122